Exploring dynamic insights from data using AI agents
With the irruption of prompting interfaces enabled by Large Language Models (LLMs), we wondered how possible it is to leverage AI agents to enable more dynamic decision-making through plain language interaction with data.
Participants:
Damian Calderon
Ignacio Orlando

— Bring those spreadsheets, sailor.
Typically, getting to a new “insight” requires collaboration with a Data Analyst to understand the new request thoroughly, followed by a team effort to analyze multiple data tables, integrate them, gather relevant statistics, and determine the best way to present this information within the application. Decision-making tools are therefore quite rigid platforms, in which user interaction is reduced to consuming what’s available on a screen. This lack of flexibility limits their usability to very specific scenarios, limiting them extensively.
How might we make user interaction with business intelligence tools more dynamic?
The hypothesis
The recent development of AI agents supported by Large Language Models (LLMs) offers a promising new way for interacting data. Based on a predefined set of actions, AI agents take a request from the user as written in plain English, and, using language as a proxy for reasoning, devise a step-by-step plan to craft an answer using those actions. With experiments in benchmark toy tests showing quite surprising results, we cannot help but wonder: can we craft new business intelligence applications in which users can retrieve new insights from a prompt box right next to the dashboard? We assume that by allowing users to articulate direct questions to data in natural language, these tools (and their associated data) will become more useful and usable for them.
Can we improve flexibility in business intelligence tools with AI-based assistants?

Natural language allows you to move faster and leaner: you’re in much finer control of your movement.
Potential use cases
For every experiment we conduct, we dedicate time to think about how it can be applied beyond the initial scope. Here are the top ones we thought for Caramel:
More informed decision-making
Dynamic decision-making by asking questions to retrieve new insights directly from business dashboards.
Deeper data exploration, to discover missing data points, errors, and opportunities.
Financial analysis
Automated generation of financial reports, e.g. by simply dictating what you want to see.
Identify potential risks and financial anomalies not covered by the existing tool.
Strategic planning
Enable thinking partners for “what-if” questions about potential future outcomes and trends.
Generation and monitoring of new key performance indicators (KPIs)
We performed our experiment using Carmelo, an internal business intelligence tool that allows our leadership teams to monitor the overall status of the company at a single glance. We used financial and strategic data automatically extracted from this tool to experiment with, obfuscated to ensure security and prevent leaks of sensitive information.
Before implementing our AI-powered prototype, we performed interviews with the main stakeholders and users of Carmelo, to survey use cases for a free text interaction tool, and to map a wishlist of “futuristic” features. This helped us to collect common questions they’d like to ask to the data and map them to potential use case scenarios.
We then used this information to implement a fully functional prototype. While doing so, we used that as an opportunity to evaluate the maturity of the existing frameworks for implementing AI agents, going beyond their benchmarks in toy sets and exploiting them in our own tables. All observations and decisions were documented on a Miro board, including an in-depth mind map with successes and failures, and ideas for further development and improvements.
After the experiment, we had a few live user testing sessions in which we left stakeholders to interact with the implemented tool and surveyed common interaction patterns, likes and dislikes, and potential improvements.
The prototype
To understand the technology and the use case scenarios in a functional setting, one of our Data Scientists implemented a fully functional yet scrappy POC, that takes tabular data as input and enables users to ask questions about it, including retrieving statistics and generating plots in the wild. The whole development process took 10 hs of coding and testing.
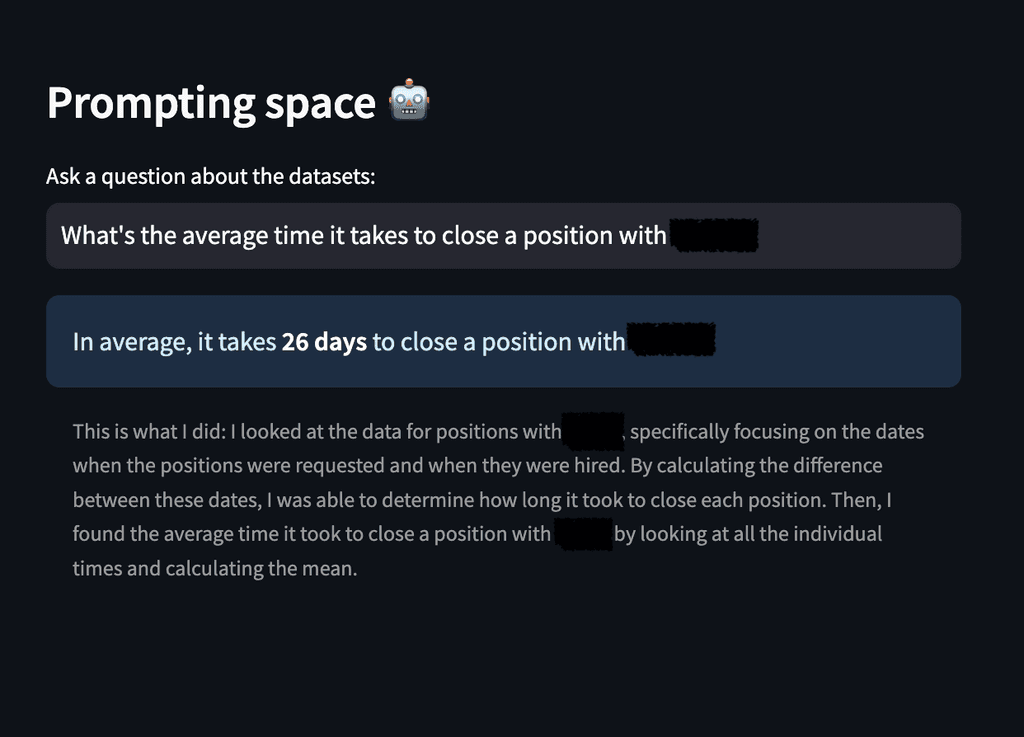
A screenshot of the live PoC with company names redacted.


The outcomes
Integrating hard data with an LLM will never be a plug-and-play activity. There are mental models, system concepts, and ambiguities we will need to take care of through refinement.
Users won’t trust an AI-based answer as they trust a dashboard, at least for now. This means we need to make an extra effort to increase user’s trust both from the ML Layer and the UI. Expanding the answers with detailed data as support material is key for this.
Failing gracefully is much more important than it seems initially. Every time the system provided a wrong answer because of the lack of refinement, user trust was heavily impacted.
We shouldn’t expect users to know what to ask. The prompting experience is new and they aren’t aware of what it covers with precision. Some users will be more explorative, but adding actionable prompt examples,and taking care of the onboarding can be a good way of controlling the initial experience.